
Написал я в ноябре заметку о том, как выбирать/приоритизировать события ИБ, на которые надо реагировать в SOC в первую очередь. Это был один из возможных вариантов, с которым я сталкивался в свое время. Эта заметка вызвала совсем небольшое обсуждение в одном SOCовском чатике и в ответ на мою заметку Сергей Солдатов написал свою. Я подумал, что можно вступить в заочную полемику с Сергеем, лишний раз подтвердив правила двух блогеров поИБэ от Сергея Борисова, сформулированные ими еще в 2014-м году.
Если вкратце, то Сергей предлагает свой подход к приоритизации инцидентов, который выглядит следующим образом:
- Внешний аутсорсинговый SOC приоритизирует инциденты исходя из своего понимания угроз и ущерба от них. Такой вариант он описал еще в 2016-м году.
- Внутренний SOC, получив данные от аутсорсингового, добавляет в них контекст, связанный с критичностью атакуемых активов, бизнес-процессами и т.п.
Лично мне такой вариант не очень близок и на то есть несколько причин. Во-первых, он подразумевает наличие внешнего SOC, что бывает очень и очень редко (от общего числа организаций, конечно). Еще реже организации используют два SOCа — внешний и внутренний.
Пару лет назад я видел статистику, что в мире существует около 3000 SOCов. Разумеется речь идет о более менее адекватных центрах с выстроенными процессами; пусть и не всеми. То есть просто наличие SIEM, TIP и SOAR вряд ли можно рассматривать как наличие SOCа. Думаю, за пару лет число SOCов подросло, но даже если вдвое, то все равно это капля в море.
Во-вторых, по версии Сергея внешний SOC отталкивается от своего знания угроз и приоритизирует инциденты, опираясь на него. В качестве примера он приводит такой — если у вас орудует APT, то это инцидент высокой степени опасности, а если подтвержден ущерб от нее, то инцидент становится критическим. Но, блин, это же не совсем так.
Начнем с того, что мы не знаем, что такое APT. Какой-нибудь Sandworm — да, безусловно. Но опасен ли он для вас, если вы живете и работаете в России? Нет. Если верить отчетам, по нашей стране они не работают. Но самое главное даже не в этом, а в том, что вам нужно сначала запариться с атрибуцией и только потом уже приоритизировать инциденты. По нескольким событиям от NTA и. EDR или по нескольким идентифицированным техникам в SIEM такая атрибуция малореальна. А если против вас вообще не действует APT или APT еще не атрибутирована никем?
Другой пример — вредоносное ПО, которое может нанести ущерб. Но откуда внешний SOC вообще может знать что-то об ущербе для конкретной организации? Ниоткуда. Такой SOC будет опираться на среднюю температуру по больнице, что может (и будет) давать сбой в конкретной организации. Представим, что внешний SOC «работает» по всему миру и среди его основных клиентов финансовые организации. Откуда ему знать про опасность угроз промышленным предприятиям в России? У него же нет фокусировки на это и его оценки могут отличаться от реальной. И другой SOC, работающий именно с отечественной промышленностью, может иметь совсем иную оценку приоритетности угрозы. То есть мы приходим ровно к тому, о чем сам Сергей и пишет:

Дальше Сергей пишет, что по его опыту инфраструктурные компоненты (к которым он относит и IDM-решения) имеют наибольшую (я так думаю, что именно наибольшую, так как в тексте написано «нибольшую», что может означать и «небольшую») критичность «по умолчанию». Но компонент компоненту рознь. Если речь идет о коммутаторе уровня ядра или виртуальном свитче, обслуживающем виртуальные же сервера в ЦОДе, то это одна история. Но если это просто точка доступа Wi-Fi или маршрутизатор в удаленном, малозначащем офисе, то это совсем другая история. И уровень критичности совсем разный, хотя во всех случаях мы говорим об инфраструктурных компонентах.
Иными словами, чтобы снизить число ложных срабатываний, внешний SOC должен иметь представление о критичности узлов, которые он берет на мониторинг.
Сергей, отстаивая по понятной причине ценность гибридной модели «внешний + внутренний SOC», пишет, что внешний SOC, которым он и руководит, не способен ввиду своей универсальности и фокуса на инфраструктурную ИБ учитывать критичность активов своих заказчиков (а как же политики multi-tenant?). И добавляет, что это и невозможно, так как у разных заказчиков разные оценки критичности инцидентов.
Блин, но ровно про это я и писал и говорил, что без понимания критичности активов, знания целевых и ключевых систем, внешний мониторинг становится не очень эффективным.
Но я прекрасно понимаю внешние SOCи, которые так утверждают, так как иной подход требует совсем иных усилий и ответственности. А за них не все готовы платить, что и заставляет аутсорсинговые SOC, в массе своей, пропагандировать историю универсальности своих услуг.
С чем я с Сергеем согласен, так это с позицией, что основой приоритизации инцидентов является ущерб. Но Сергей обходит молчанием вопрос, как оценивать ущерб, и я его понимаю. Это очень непростая задача.
- Статья «Финансовая сторона инцидента ИБ«
- Бесплатный онлайн-курс «Как оценивать ущерб в кибербезопасности«
- Заметка «Пять уровней зрелости оценки ущерба от DDoS-атак«
- Заметка «Оценка ущерба от инцидентов ИБ (возможный подход)«
- Заметка «Когда безопасность только мешает бизнесу, нанося ему реальный финансовый ущерб«
Ну и чтобы моя заметка была не просто алаверды и комментарием на комментарий, а несла еще и пользу, то приведу в качестве примера различные варианты приоритизаций инцидентов ИБ, у каждого из которых есть свои особенности, свои достоинства и недостатки. Вот, например, приоритизация по типу активов, которые задействованы в инциденты в качестве источника, назначения или промежуточного узла:

На днях по радио услышал слово «дестинация». Сначала не мог въехать, что имелось ввиду, а потом уже дошло, что речь о destination. Какое-то издевательство над русским языком.
В примере ниже приоритизация зависит от нескольких факторов — критичность, тип актива, уровень последствий:

В обоих представленных вариантах от вас потребуется выстроенного процесса инвентаризации активов, но в первом случае на этом можно и ограничиться, а во втором вам все-таки придется учесть еще и их критичность.
В примере ниже, в котором вместо уровня «критический» вводится вариант «дьявольский», приоритизация идет от уровня компетенций нападающих:

В этом варианте также несколько факторов учтено. Наиболее опасные инциденты наносят вред жизни и здоровью людей:
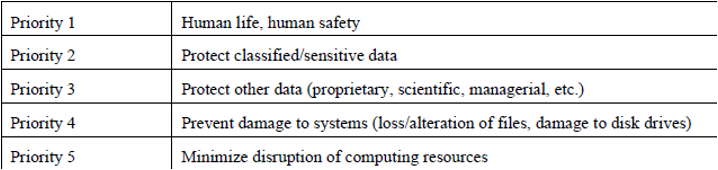
Данный вариант близок к описанному Сергеем — приоритеты выставляются в зависимости от серьезности атаки:

В схеме ниже приоритизация привязана к ущербу:

Еще один вариант:

Все вышеперечисленные варианты основаны на однофакторной приоритизации, что с одной стороны очень просто в реализации, но не учитывает множества нюансов и параметров. Бывают варианты, когда мы не можем оценить ущерб по одной единственной шкале и тогда предлагаются несколько шкал со своими градациями, которые и используются в зависимости от инцидента. Например, вариант приоритизации в зависимости от типа и масштаба ущерба, а не просто качественной оценки «высокий», «средний» и «низкий»:

А вот в этом варианте у вас не просто разные виды ущерба, но и вообще разные критерии оценки — и ущерб, и типы активов, и количественные характеристики:

В варианте ниже на приоритет влияет время недоступности бизнес-систем разного типа в финансовой организации:
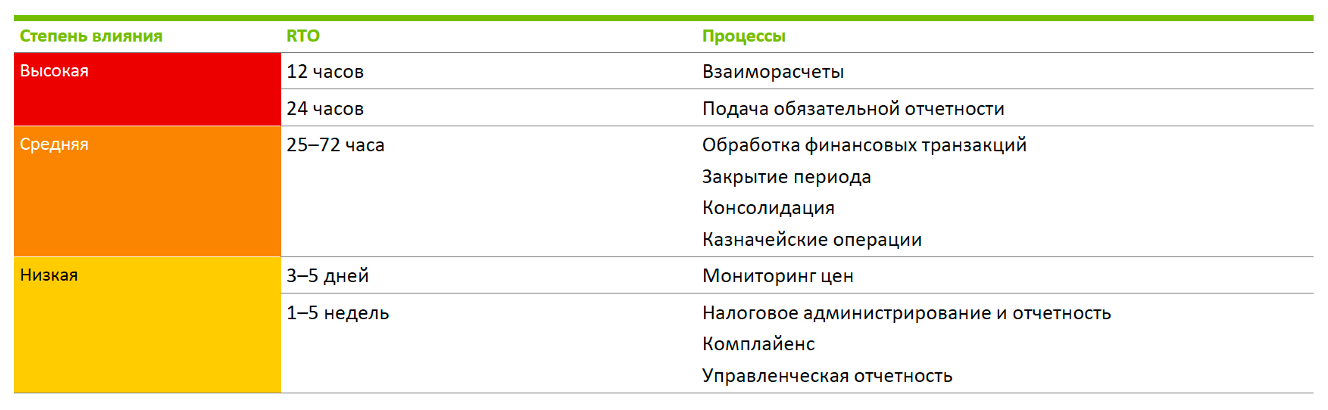
А вот этот пример интересен тем, что показывает, что приоритет вообще может меняться в зависимости от времени обнаружения или наступления последствий инцидента:
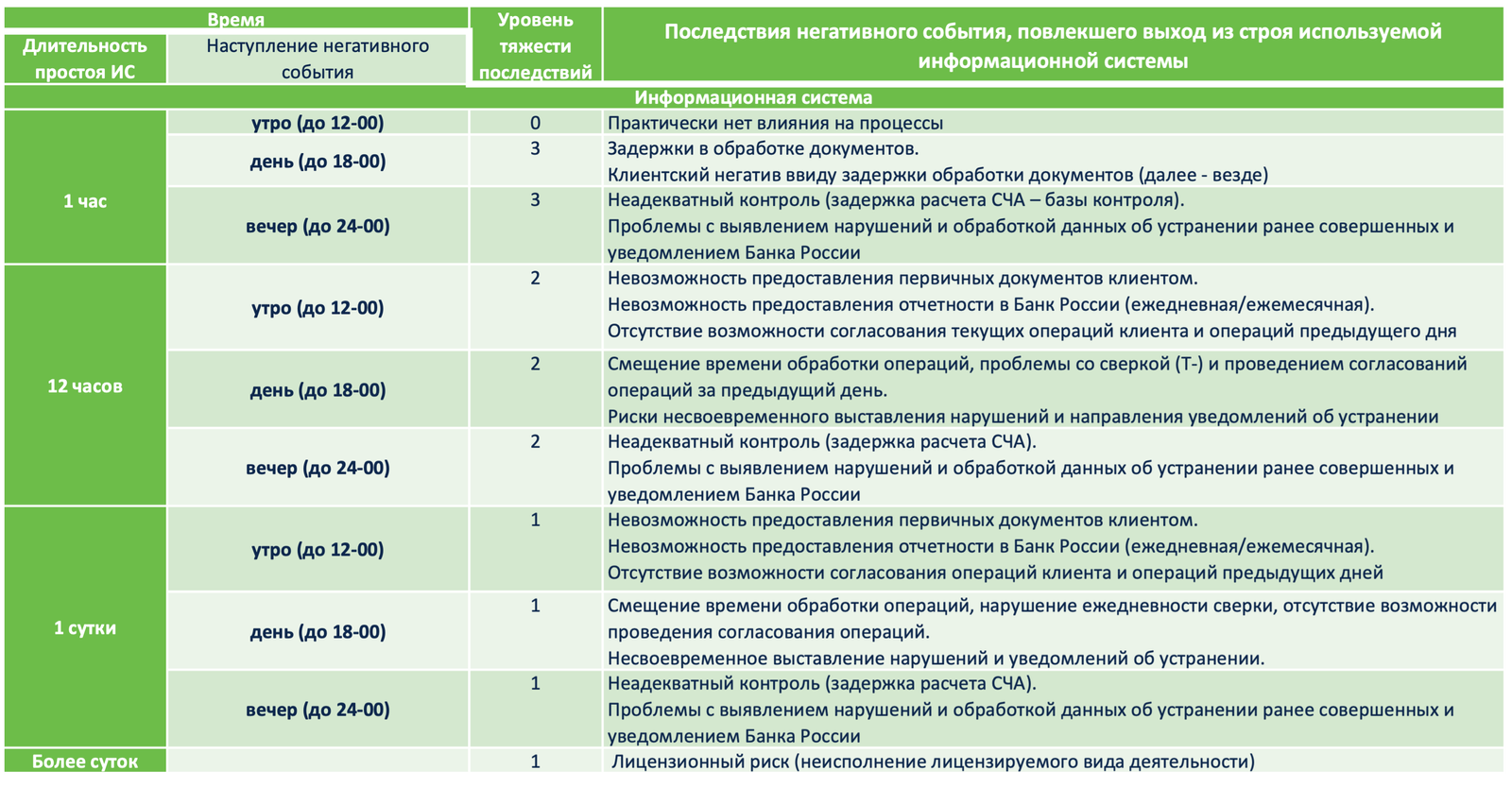
Видите, сколько вариантов приоритизации может быть? И каждый из них применялся и применяется в той или иной зарубежной или отечественной организации. Так что все они имеют право на существование. Я ни в коем случае не претендую на истину в последней инстанции (да и откуда ей взяться при таком количестве вариантов). Просто хотел показать, что у этой задачи есть множество разных вариантов решений, а не только один. И выбирать их только вам. Допускаю даже, что вы попробуете разные варианты, прежде чем придете к чему-то вас устраивающему. А с ростом зрелости вы может придумаете и свой, многофакторный вариант приоритизации.
В любом случае обратите внимание, что процесс приоритизации инцидентов только кажется достаточно простым (ну а что, только градацию придумать). На самом деле за ним стоит очень большая работа по инвентаризации и управлению активами, выстраиванию коммуникаций с бизнесом для оценки ущерба и т.п. А это все, ой, как непросто. Это вам не в блоге написать.
Совет: если вам кто-то предлагает (или даже навязывает) свой вариант приоритизации (особенно в случае с внешним SOC), то пусть вам обоснуют правильность именно этой схемы и насколько она применима к вам. А самое главное, пусть расскажут, что вам надо будет сделать, чтобы учесть специфику вашей организации с точки зрения критичности активов, размера и типа ущерба, целевых и ключевых систем и т.п.






