
Помню, проходил я несколько лет назад стажировку в одном SOC, и в первый же день я задал коллегам сакраментальный вопрос — а как вы выбираете, на какие сигналы от SIEM/EDR/NTA/NDR реагировать, а какие можно отложить «на потом»? Ведь при миллионах и миллиардах событий безопасности, которые детектируют различные сенсоры и «сдают» в SOC, потеряться в них несложно. И рассказали мне лайфхак, которым я бы тоже хотел поделиться.
Дальше я исхожу из предположения, что вы знаете, что такое матрица MITRE ATT&CK.
Начнем с того, что инциденты ИБ никогда не бывают одноходовыми и состоящими только из одного события безопасности.
На самом деле бывают и это говорит о том, что вы не смогли адекватно настроить имеющиеся средства мониторинга или и вовсе их не имеете. И тогда у меня для вас плохие новости…
Возьмем к примеру обычное внешнее сканирование уязвимостей web-сайта. С точки зрения матрицы MITRE ATT&CK это всего одна тактика (ТА0043) и одна техника Т1595 (активное сканирование). В реальности за этим сканированием стоит еще несколько техник (Т1590, Т1592 и т.д.,) но это не так уж и важно, да и отследить их достаточно проблематично. Само по себе сканирование не может быть инцидентом ИБ (кто бы что там не говорил и чтобы не писал в нормативных документах). Ping — это обычная жизнь в Интернете и отделить пинг от сканирования достаточно сложно. Ну если сканирование не является перебором открытых портов на узле или перебором доступных IP-узлов из диапазона.
Иными словами, реагирование на каждую сработку вашей СОВ или NTA на внешнее сканирование смысла не имеет — будет только отжирать ваши ресурсы.
Теперь посмотрим на какой-нибудь mimikatz. Он попадает уже в пару тактик — повышение привилегий (ТА0004) и доступ к учетным записям (ТА0006) и мы даже интуитивно понимаем, что mimikatz серьезнее обычного сканирования. Идем дальше и посмотрим на Cobalt Strike, как пока еще все популярный фреймворк. Он попадает уже в 7 тактик — повышение привилегий (ТА0004), доступ к учетным записям (ТА0006), сбор информации (ТА0007), расширение плацдарма (ТА0008), захват данных (ТА0009), управление (ТА0011) и выгрузка данных (ТА0010).
Если вы используете концепцию ФСТЭК со способами реализации угрозы, классическую версию Kill Chain или любой иной из вариант построения цепочки атаки (жизненного цикла инцидента), то это не так уж и важно.
Поэтому:
Первое правило: попадание одного или нескольких событий всего в одну тактику не требует пристального внимания, так как работа с фолсами по данному событию (событиям) займет больше времени, чем пользы от него.
Отсюда же вытекает и второе очевидное правило:
Попадание одного или нескольких событий всего в одну технику не требует пристального внимания.
Ну и промежуточный вывод:
Попадание одного или нескольких связанных событий в несколько техник MITRE ATT&CK с высокой вероятностью может говорить о реальном инциденте ИБ.
Но даже после такой обработки сигналов тревоги будет достаточно много и поэтому стоит их все разбить на три категории критичности:
- Высокая критичность
- Сигнал тревоги, который связан с обнаружением с высокой точностью двух и более тактик (не техник) MITRE ATT&CK в результате действий из одного источника.
- Сигнал тревоги, который скорее всего связан с обнаружением использования/эксплуатации трендовой или критической непатченной уязвимости.
- Сигнал тревоги, который связан с обнаружением с высокой точностью актуального или ранее встречающегося индикатора компрометации из подтвержденного инцидента ИБ.
- Сигнал тревоги, который связан с обнаружением с высокой точностью нарушителя или группировки на основе данных из источника TI высокого уровня доверия (да, источники TI тоже могут ранжироваться по уровням доверия).
«С высокой точностью» в данном случае означает уверенность на 90%, что сигнал тревоги не фолсит, а является истинным (true positive). «Скорее всего» в данном случае означает уверенность на 50%, что сигнал тревоги не фолсит, а является истинным (true positive). Вычисление уровня точности обнаружения и уровня доверия к TI-источникам — это отдельная тема, которой я уже частично касался.
- Средняя критичность
- Сигнал тревоги, который связан с обнаружением с высокой точностью двух и более техник MITRE ATT&CK в результате действий из одного источника.
- Сигнал тревоги, который связан с обнаружением с высокой точностью нарушителя или группировки, который, согласно источнику TI, может атаковать индустрии, в котором работает и ваше предприятие.
- Низкая критичность.
- Тут могут быть свои критерии (например, сигнал тревоги, который связан с обнаружением использования/эксплуатации непатченной уязвимости среднего или низкого уровня критичности), но это уже не так важно.
Сильно ли мы сократим число сигналов тревоги после прохождения описанной выше процедуры классификации? Да, но не так, чтобы и очень много. Да, мы отсечем совсем шлак и фолсы, но остальных событий, пусть и приоиритизированных, будет все равно немало. А представьте на минутку, что у вас есть с разницей в 4:58 минут (меньше времени на взятие инцидента в работу) прилетело два одинаковых сигнала тревоги, которые связаны с обнаружением использования/эксплуатации трендовой или критической непатченной уязвимости на узлах 10.0.1.15 и 10.2.37.86. И на что реагировать в первую очередь?
Важно учитывать данные об узлах, с которыми связаны обнаруживаемые события безопасности!
Чтобы сделать это, стоит ответить себе на следующие вопросы:
- Это целевая или ключевая система для бизнеса, от функционирования которой зависит достижение операционных или стратегических целей предприятия?
О том, что такое целевая или ключевая система можно почитать на сайте проекта «Резбез». В качестве примера можно назвать не только системы типа 1С:Предприятие или Интернет-банк, но и конвейер разработки CI/CD (для разработчика ПО), системы, с которых осуществляется доступ к инфраструктуре клиентов (вспомните кейс Okta, SolarWinds, Kaseya и т.п.)
- Это система коммуникаций?
В противном случае можно столкнуться с кейсом, который я описывал у себя в Телеграм-канале.
- Это legacy-система, которая может вести себя нестабильно и непредсказуемо?
Иногда такие системы будут попадать в исключения!
- Это система управления ИТ/ИБ-инфраструктурой?
О таком примере писал в июне НКЦКИ! Но это может быть и что-то другое. Например, SIEM (как в кейсе с Sumo Logic) или корпоративное хранилище паролей и учетных записей.
На основе ответов на эти вопросы вы сможете приоритизировать все свои активы, например:
- Высокой критичности (доступ к активу позволит нанести бизнесу катастрофические последствия, в т.ч. привести к масштабной компрометации)
- Доступ к активу может привести к реализации недопустимых событий / катастрофических последствий
- Доступ к активу может привести к компрометации >75% ИТ/ИБ-систем
- Доступ к активу может привести к компрометации большого числа других организаций или небольшого числа важных клиентов.
- Средней критичности (использование актива позволит в будущем скомпрометировать другие узлы)
- Активы используются службой ИБ для мониторинга и реагирования на инциденты
- Низкой критичности.
Имея информацию о приоритете узла, данные о котором вам поступают в сигнале тревоги, и о приоритете самого сигнала, вы можете приоритизировать работу с ними в соответствие с представленной матрицей:
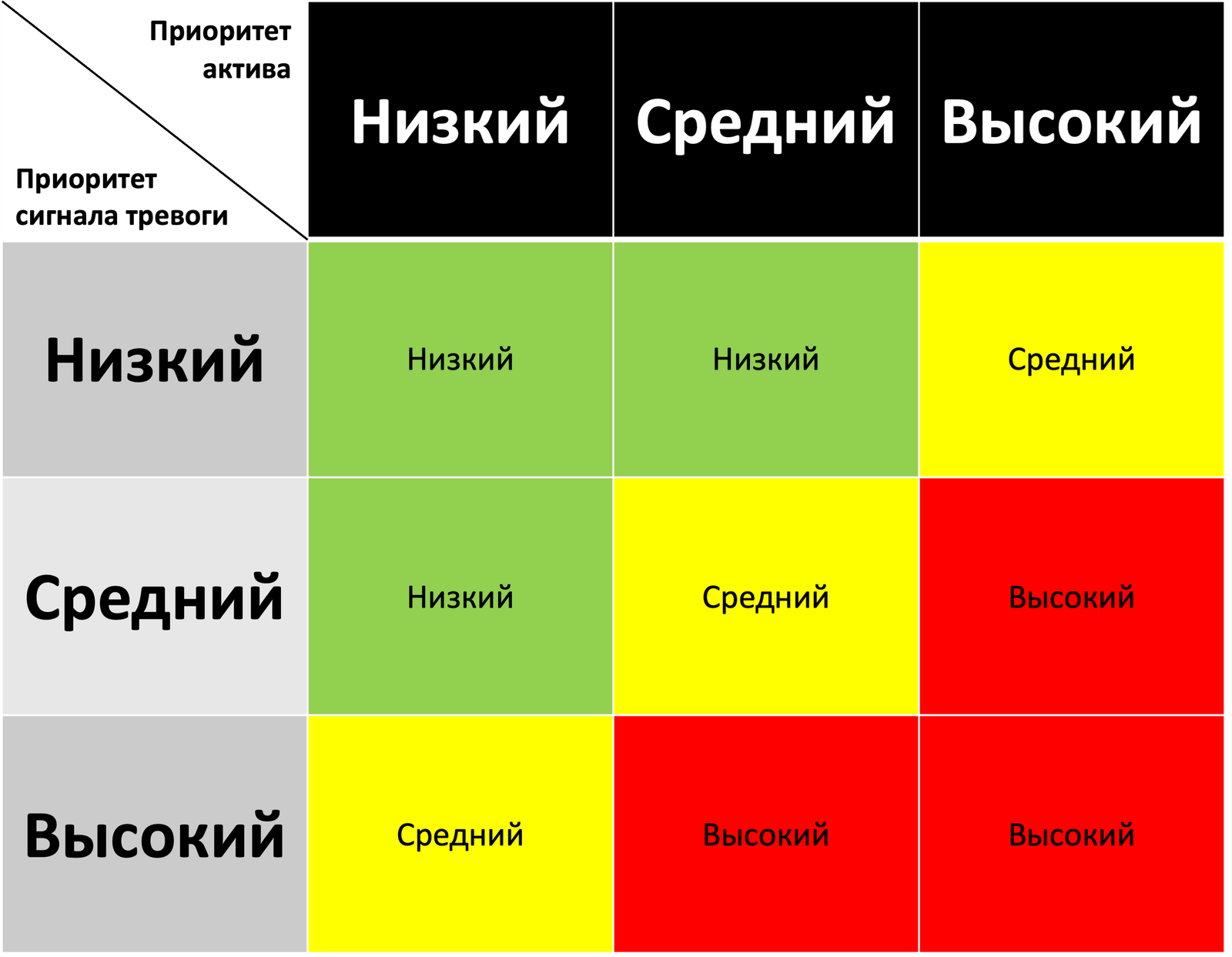
Насколько данный подход является рабочим? Вполне, так как я видел как по нему работают в одном из SOCов и делают это достаточно успешно. Подойдет ли он вам? Тут вам решать. Вам точно придется уточнить градации по обеим факторам, учитываемым при приоритизации, но задача эта несложная. Возможно, вы возьмете за основу описанные мной факторы, возможно у вас будут свои дополнительные. Я не настаиваю на истине в последней инстанции. Задача же помочь найти способ сократить число событий, с которыми работает аналитик SOC и при этом приоритизировать оставшиеся, чтобы компания получила максимальную пользу от этого.







