Допустим, я убедил вас в прошлой заметке, что быть зависимым от внешнего разработчика (неважно — отечественного или зарубежного) контента обнаружения (сигнатур атак, use case, правил SIEM и т.п.) плохо и вы решили, что да, пора начать писать контент самому (хотя так удобно от кого-то зависеть, чтобы все свои промахи сваливать на кого-то). Как лучше всего это сделать? Мне кажется, для этого как нельзя лучше подходит концепция X-as-a-Code, а в нашем случае Detection-as-a-Code, которая позволяет внедрить процесс непрерывной разработки и тестирования нового контента обнаружения угроз в постоянно изменяющейся среде по аналогии с тем, как выстраиваются современные практики DevOps.
Задача Detection-as-a-Code заключается не только в выстраивании процесса непрерывного написания нового контента обнаружения, но и в повышении качества этого контента и снижении числа ложных срабатываний, которые сводят на нет все преимущества технологии обнаружения и даже привели к тому, что много лет назад родилось высказывание, что IDS мертвы. Им на смену пришли SIEM, которые сейчас тоже находятся в стадии присмерти из-за большого числа ложных срабатываний, связанного с ростом числа событий безопасности, которые должны обрабатывать системы мониторинга. Это вообще гонка брони и снаряда, когда сначала технология вас устраивает, а потом наступает некий предел и начинаются проблемы, которые пытаются решить новой технологией, у которой тоже наступает предел и т.п. Это тупиковый путь развития технологий обнаружения, который можно было попробовать хотя бы замедлить за счет не увеличения числа правил обнаружения и скорости их выпуска, а за счет роста их качества. И Detection-as-a-Code позволяет это реализовать.
Подход Detection-as-a-Code позволяет не бояться, что мы что-то сломаем, так как после создания контента он не сразу “деплоится” в систему обнаружения, а проходит проверку, на которой могут быть выявлены все косяки. Но мы должны вспомнить, что в DevOps, откуда и пришел DaaS, одним из ключевых является непрерывность (не зря же в аббревиатуре CI/CD целых две буквы C — Continuous). Поэтому каждый день мы (точнее инженеры по обнаружению угроз) должны задаваться вопросами:
- А написанный нами вчера контент обнаружения позволяет обнаруживать угрозу сегодня?
- Не сменилась ли логика/инструментарий/подходы у злоумышленников?
- Описанная нами в контенте логика обнаружения все еще позволяет обнаруживать угрозу?
- Не пора ли проверить и поменять контент обнаружения?
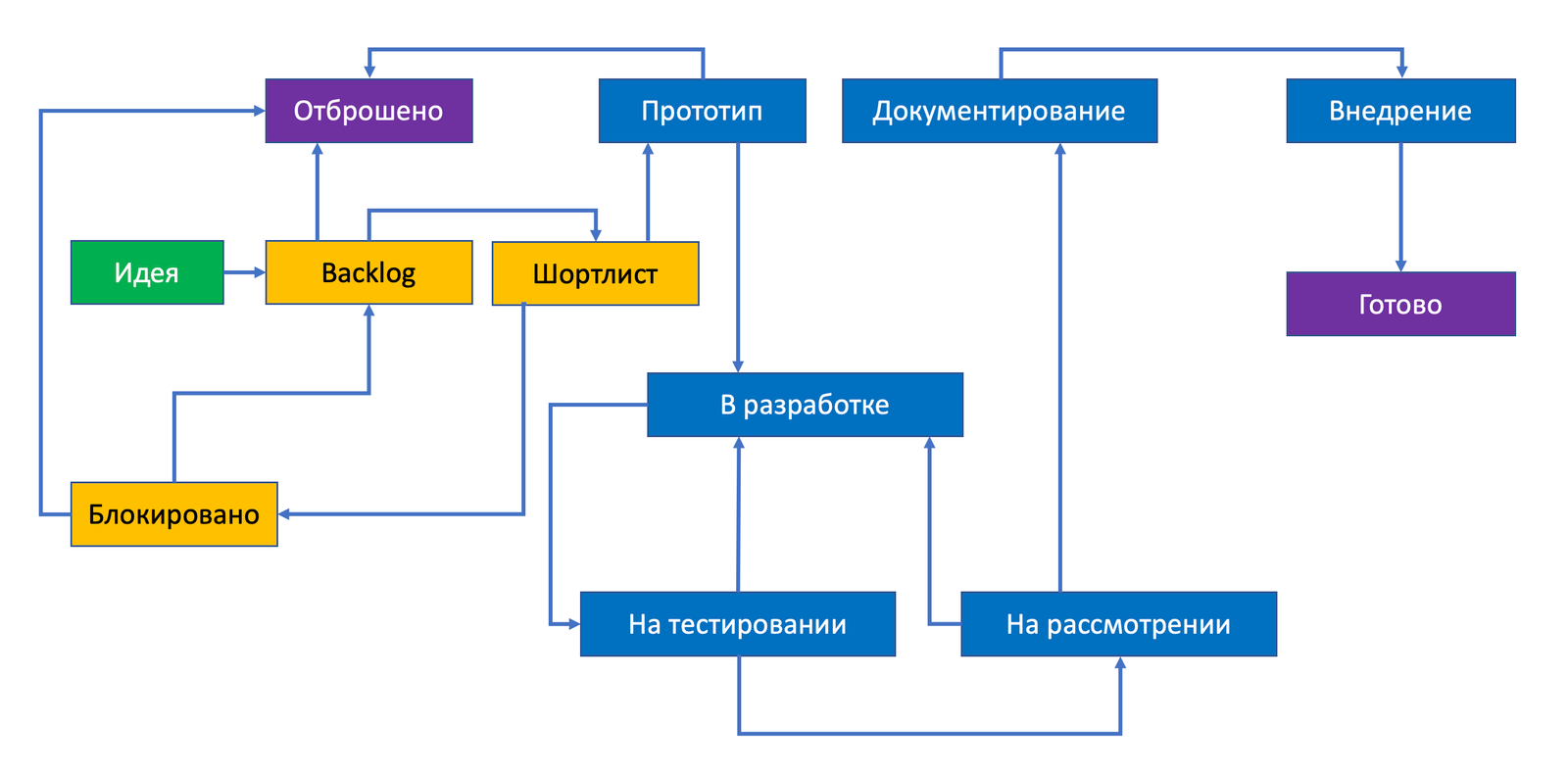
Эта ежедневность вопросов подводят нас к мысли, что процесс разработки контента обнаружения должен длится не очень долго и вполне логично, что мы плавно подходим к мысли о гибкой разработке. Слово Agile в России часто подменяется нелицеприятным “отжайл” и несет некую негативную коннотацию. При этом сама суть разбиения крупного процесса на множество повторяемых небольших шагов остается достаточно правильной и хорошо применимой в Detection-as-a-Code. Специалисты по обнаружению должны следовать структурированному процессу (планирование — написание контента — тестирование — внедрение). Не нравится вам Agile, замените это слово на Scrum или Kanban. Любая система, поддерживающая Kanban-доски, подойдет для отслеживания статуса контента обнаружения (Jira была бы неплохим вариантом, но 24 февраля немного смешало карты). Например, это могло бы выглядеть так:
Писать контент обнаружения я бы начал с упомянутых в прошлой заметке языков Snort, Yara, Sigma, для которых существуют уже готовые базы правил, которыми обмениваются специалисты по всему миру. Есть компании и эксперты, которые придерживаются подхода, что писать контент обнаружения надо на универсальном и гибком языке, таком как Python, так как это дает больше преимуществ, чем использование специфических, ориентированных на конкретные задачи языков. Но я считаю, что начинать с него точно не стоит. Может быть потом, когда вы решите, что и чужие (пусть и open source) системы обнаружения угроз вам не нужны, вы перейдете на Python, с помощью которого вы будете не только писать контент обнаружения, но и обнаруживать угрозы (но не факт).
Еще одним преимуществом Detection-as-a-Code является возможность повторного использования уже написаного контента обнаружения. Да, в чистом виде сложно будет применить повторное применение контента обнаружения так, как это используется в мире программирования. Очевидно, что какую бы фишинговую кампанию мы не взяли, они все используют схожие методы, но разные формулировки, тесты, вредоносные ссылки или аттачи. Почему бы не использовать уже ранее написанный контент для описания новой вредоносной кампании? А может быть мы со временем сможем любой фишинг описывать одним общим шаблоном, наследуя от него только какие-то специфические нюансы (да-да, речь о концепции наследования из объектно-ориентированного программирования). Та же история идеально ложится на написание use case для деятельности SOCов. Например, мне надо написать плейбук для обнаружения попыток манипуляции административным доступом. Очевидно, что существует общий набор действий, который мне надо проверить/обнаружить независимо от системы (Windows, Linux, macOS, Cisco, Oracle, Postgress, AWS и т.п.). А дальше уже начинают нюансы конкретной платформы. Повторное использование помогает ускорить создание плейбуков для каждой новой платформы, которую мы будем использовать у нас в компании. Или, например, я написал правила для ACL для межсетевых экранов Cisco Firepower, но компания решила, что она идет в облака и часть приложений и сервисов будут переносы в облачные среды. В обычной жизни нам придется переписывать все заново, а в случае применения Detection-as-a-Code мы можем воспользоваться уже имеющейся библиотекой правил для существующего МСЭ и просто транслировать их под новые условия — возможно это будет тот же МСЭ Cisco (только в виртуализированной форме исполнения), возможно это будет какой-нибудь AWS Network Firewall, а может и вовсе иное наложенное решение. Но правила-то будут те же — вам просто придется применить их не к физической сети, а к VPC. И тоже самое будет применено и к обычным сигнатурам атак для IDS, шаблонам для NDR и т.п.
А вот использование подхода с созданием библиотеки контента (на базе локального репозитория или Git) можно только приветствовать. Это позволяет иметь отчуждаемый от технологии/инструмента обнаружения источник информации, который можно без особых проблем ”переносить” от решения к решению (с оговорками), от компании к компании, а также делиться им при таком желании с комьюнити. Да и пополнять свою библиотеку, построенную по неким правилам, чужим контентом также будет проще, чем ориентироваться на встроенный в применяемый продукт проприетарный формат хранения сигнатур и правила обнаружения.
Применение методов тестирования (Quality Assurance) к контенту обнаружения отличает Detection-as-a-Code от обычно применяемых подходов к написанию контента обнаружения. В рамках QA мы можем выявить слепые зоны для разработанного контента, проверить его на ложные срабатывания, расширить на нужные источники телеметрии, тем самым повышая его эффективность без разрастания числа правил обнаружения. А то помнится мне, когда 5 лет назад началась эпидемия WannaCry некоторые вендоры писали под каждую модификацию (а их было не менее 400) свою сигнатуру, что позволяло им хвалиться числом сигнатур атак в своих решениях, но ничего не говорило об их качестве. Подход с точки зрения тестов контента обнаружения также позволяет чуть-чуть почувствовать себя хакером, который также, прежде чем пойти в виртуальный бой, тестирует свое вооружение на обнаруживаемость, подкручивает что-то, подтюнивает, а потом каааак жахнет. Вот и инженеры по обнаружению постепенно докручивают свой контент, внося в него улучшения, ввода исключения и т.п., попутно документируя свои изыскания в Jira или Redmine (если продукты Atlassian стали недоступны), чтобы можно было всегда к ним вернуться и понять, почему было принято то или иное решение.
Как проводить тестирование контента обнаружения? Тут мне видится несколько, по правде, вполне очевидных, вариантов — статическое и динамическое тестирование. Первый вариант самый простой и очевидный — в нем тестирование управляется инженерами, которым, увы, свойственно ошибаться. При росте числа инженеров и правил, это может стать проблемой. Поэтому нужна автоматизация и я бы, в качестве примера, мог назвать следующие варианты:
- Visual Studio Code с расширением для YAML позволяет подсвечивать ошибки в синтаксисе правил SIGMA, а скрипт sigmalint позволяет проверять правила SIGMA на соответствие схеме языка.
- Скрипт sigmac позволяет проверить правильность написания правила для того или иного средства мониторинга ИБ, а скрипт sigma-test позволяет определять тестовые сценарии для правил SIGMA и проверять, что разработанное правило позволяет его детектировать.
- Для тестирования правил Yara можно использовать функцию Retrohunt в VirusTotal, проект Касперского KLARA или онлайн-сервис Yara Scan Service.
Статические тесты не позволяют выявить проблемы в контенте в процессе его отработки в реальном времени. Эту задачу решают динамические тесты, которые требуют ”участия” систем обнаружения угроз (например, SIEM или NDR), которые могут давать обратную связь в рамках непрерывного конвейера CI/CD. Например, число сработок правил или длительность поиска могут быть свидетельством неправильно написанного контента, которые могут быть проанализированы бе участия человека. Внутренние системы обработки ошибок в средствах мониторинга тоже позволяют выявить некачественный контент обнаружения. Правда, это еще не совсем динамические тесты в истинном смысле.
Зато, в отличие от классического DevOps, в ИБ существует возможность организации динамических тестов с помощью атак, которые как раз и отвечают на вопросы “мой контент позволяет обнаружить угрозу” и “мой контент все еще обнаруживает угрозы?”. Небольшие тесты, подготовленные в рамках фреймворка Atomic Red Team, разработанного компанией Red Canary, представляют собой постоянно пополняемую коллекцию скриптов для тестирования систем обнаружения угроз. Правда, с этими тестами есть и своя засада. Это тоже код, который тоже надо тестировать в рамках концепции DevOps, то есть применять к нему тот же конвейер CI/CD и тоже тестировать его на предмет корректности. Тут придется где-то поставить точку, чтобы не загонять себя в бесконечный цикл. Она может быть проставлена на уровне фреймворка Atomic Red Team, которому мы можем доверять. А можно перепроверять его с помощью собственной команды Red Team, которая не только будет подтверждать корректность тестов фреймворка от Red Canary, но и дополнять своими тестами/скриптами. Как вариант, можно использовать решения класса Breach & Attack Simulation (BAS) для автоматизации оценки эффективности написанных правил идентификации вредоносной активности.
Для запуска тестов необходимо иметь тестовую среду, которая должна копировать вашу инфраструктуру, включая и стек защитных средств. Да, это непросто, но с другой стороны, сегодня такие тестовые окружения созданы во многих компаниях для тестирования нового ПО, патчей, обновлений. Их же можно задействовать и для тестирования контента обнаружения. Сделать это можно так — запускать по расписанию нужные тесты и следить за тем, будут ли они обнаружены имеющимися средствами обнаружения, для которых мы писали контент обнаружения. Последующий анализ логов (по временным меткам) подскажет было ли обнаружение успешным на 100% (на всех нужных платформах и для всех средств обнаружения) или лишь частичным. Затем мы можем зафиксировать результаты теста в системе управления проблемами и инициировать при необходимости доработку контента обнаружения. Такая автоматизация запуска тестов позволит нам и ответить на вопрос: “мой контент все еще обнаруживает угрозы?”. Эта же тестовая среда нам позволит проверить способность нашего контента обнаруживать новые угрозы, информацию о которых мы получили в рамках обмена данными об угрозах или в рамках работы команды пентестеров/Red Team. Они смогут быстро (я надеюсь) разработать соответствующие скрипты и включить их в непрерывно действующий конвейер CI/CD.
Подход Detection-as-a-Code — это больше, чем только тестирование и снижение числа ложных срабатываний. Это еще и возможность повысить качество контента обнаружения за счет его модульности, расширяемости (кто мешает добавлять в контент новые блоки для обнаружения схожих по принципу действия угроз) и версионности (кто мешает иметь несколько версий контента с обнаружением вредоноса под разные платформы?). Не сработало? Откатились на предыдущую версию и смотрим, что в ней нужно изменить. Мы всегда можем проверить, последней ли версии контент обнаружения мы используем и если нет, то почему.
Ведение истории изменений — это еще и хороший способ не потеряться в постоянных обновлениях и при наличии более чем одного инженера обнаружения. А если посмотреть чуть шире, то и контроль и управление изменениями (change management) помогают нам регулярно возвращаться к уже написанным правилам и при необходимости переписывать их под новые требования или сделанные в инфраструктуре изменения (новые ОС, новые приложения, новые устройства, новые протоколы и т.п.).
В одной заметке достаточно сложно рассказать обо всех нюансах Detection-as-a-Code, но , если честно, и не ставил такой задачи, желая только рассказать о самой концепции и некоторых важных ее элементах, реализация которых будет уже зависеть от конкретного инструментария, используемого для обнаружения угроз и для написания контента по нему.







