
Но только попробую. Потому что тема визуализации этой темы достаточно объемна и, самое главное, зависит от целей этого самого мониторинга и реагирования. Можно ограничиться только визуализацией числа инцидентов ИБ, которые обрабатывает SOC (можно даже с динамикой изменения этого числа). Например, вот так:

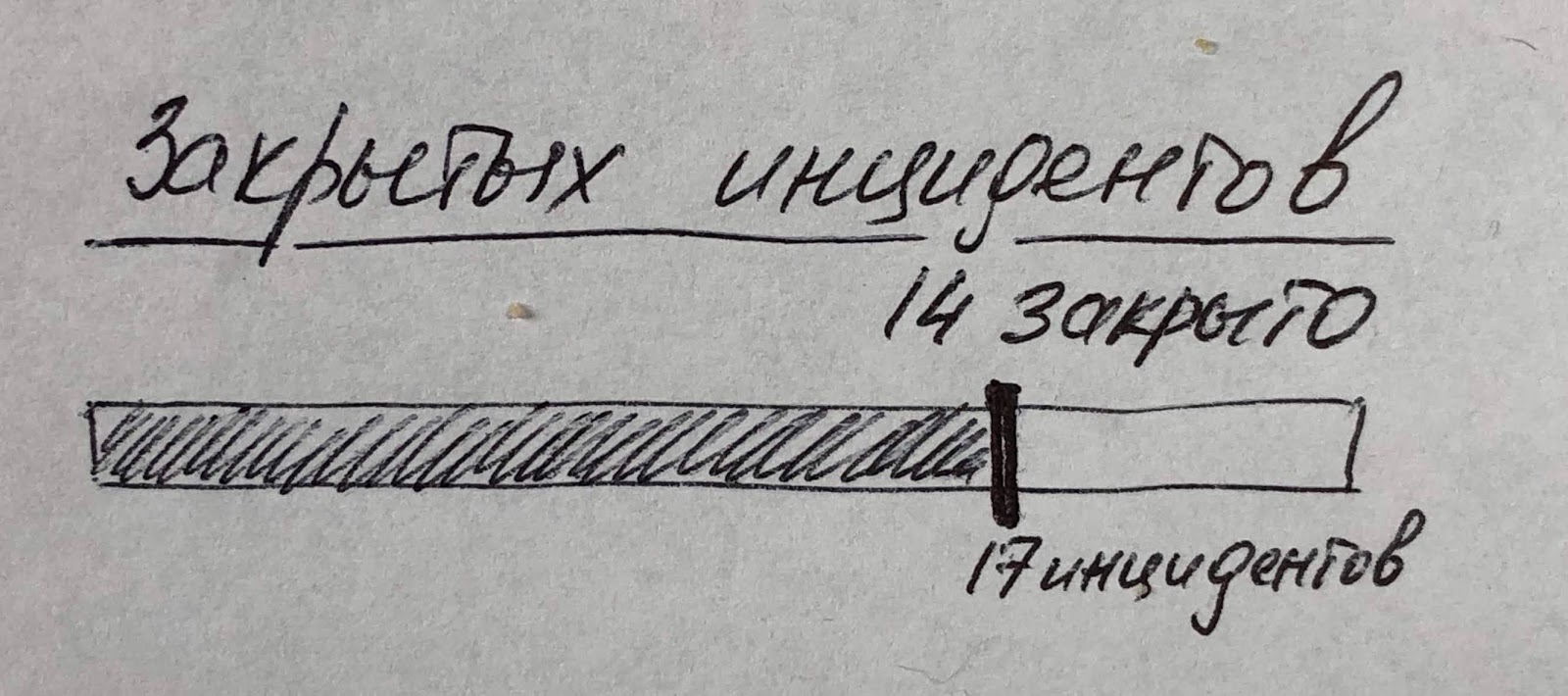
А можно копнуть глубже и посмотреть соотношение открытых и закрытых инцидентов (можно добавить еще большую детализацию, если указать тип инцидента или его приоритет или увязать инциденты с аналитиками). Показанный ниже пример интересен тем, что в нем используется не гистограмма (которая для визуализации соотношения вообще не подходит) и даже не диаграмма, которая просто показывает соотношение числа открытых и закрытых инцидентов, а «бегунок», который лучше визуализирует не только соотношение, но и стремление к цели (то есть сокращение числа незакрытых инцидентов). И тут важно помнить, что мы говорим о стремлении свести к нулю не число инцидентов (это невозможно), а число именно незакрытых инцидентов.
Смотря на рекламные материалы некоторых аутсорсинговых SOCов, удивляешься, когда SOC пишет, что они за 15 минут реагируют на инцидент. Тут либо манипуляция терминами и под словом «реагирование» они понимают «принимают в обработку» (но тогда чем тут хвалиться)? Либо речь идет о непонимании реальной работы SOC, в котором время принятия инцидента в обработку может составлять минуты (пока прилетит сигнал тревоги в SIEM, пока он скоррелируется, пока он приоритезируется). Поэтому одной из важных метрик в SOC будет время принятия инцидента в обработку первой линией. Виджет, который это будет показывать, может выглядеть так:
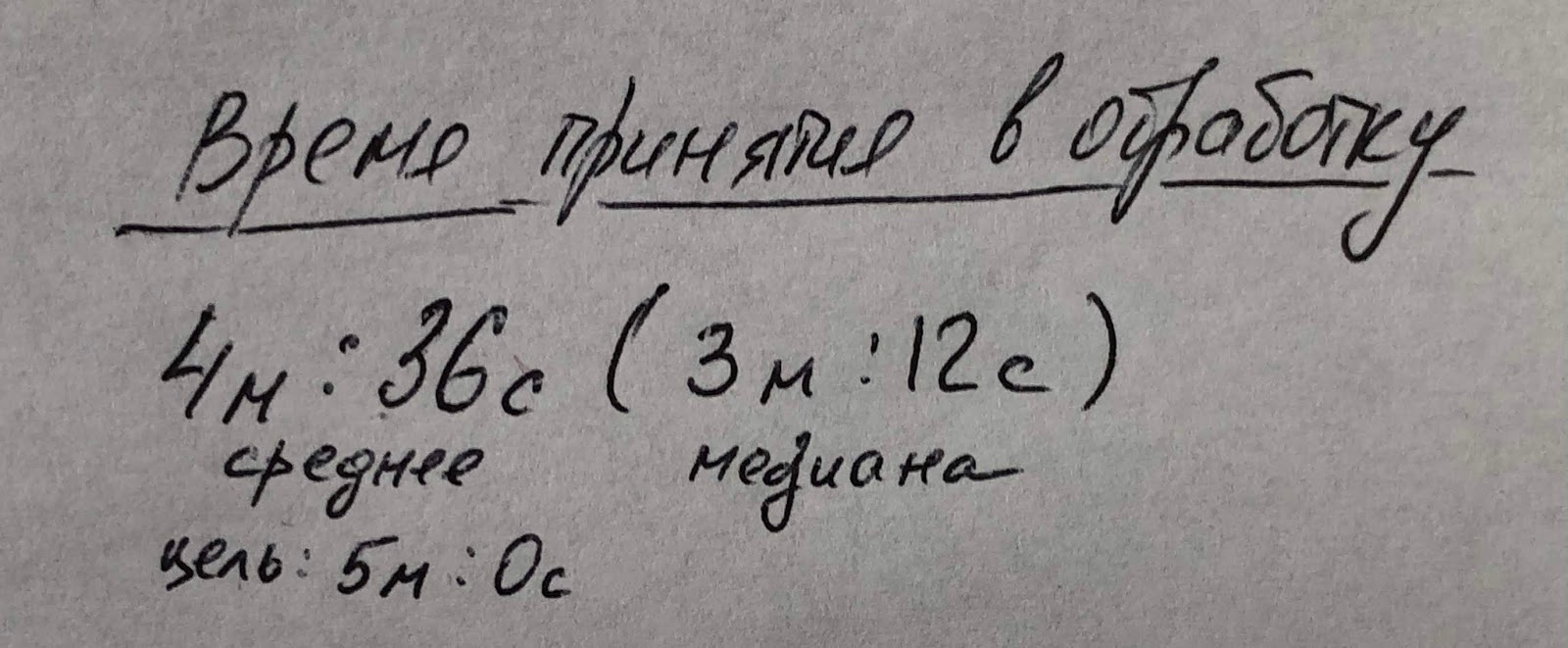
В нем не только отображено среднее время взятия инцидента в работу (можно еще детализировать для разных типов инцидентов и аналитиков; для приоритета бессмысленно), но и указана цель этого показателя. В реальном дашборде значение времени будет отображаться зеленым, если показатель находится в заданных пределах, и красным, если он вышел за границы (можно добавить еще желтый, если считать приближение к граничному значению). Обратите внимание, что помимо среднего арифметического я также добавил медиану, так как именно она лучше отражает типичное значение времени взятия инцидента в работу.
Но этот виджет показывает нам текущее значение (за указанный интервал времени), не говоря ни слова о том, какое число инцидентов из общего их числа было взято вовремя. Для этого может подойти вот такой виджет: Опять же, зеленая/красная направленная стрелка показывает нам улучшение или ухудшение (а не рост или падение) этого показателя, а зеленый или красный цвет числа покажет, вышли ли мы за установленные целевые значения или нет. Если накапливать этот показатель в течение времени, то можно будет еще строить динамику его изменения.
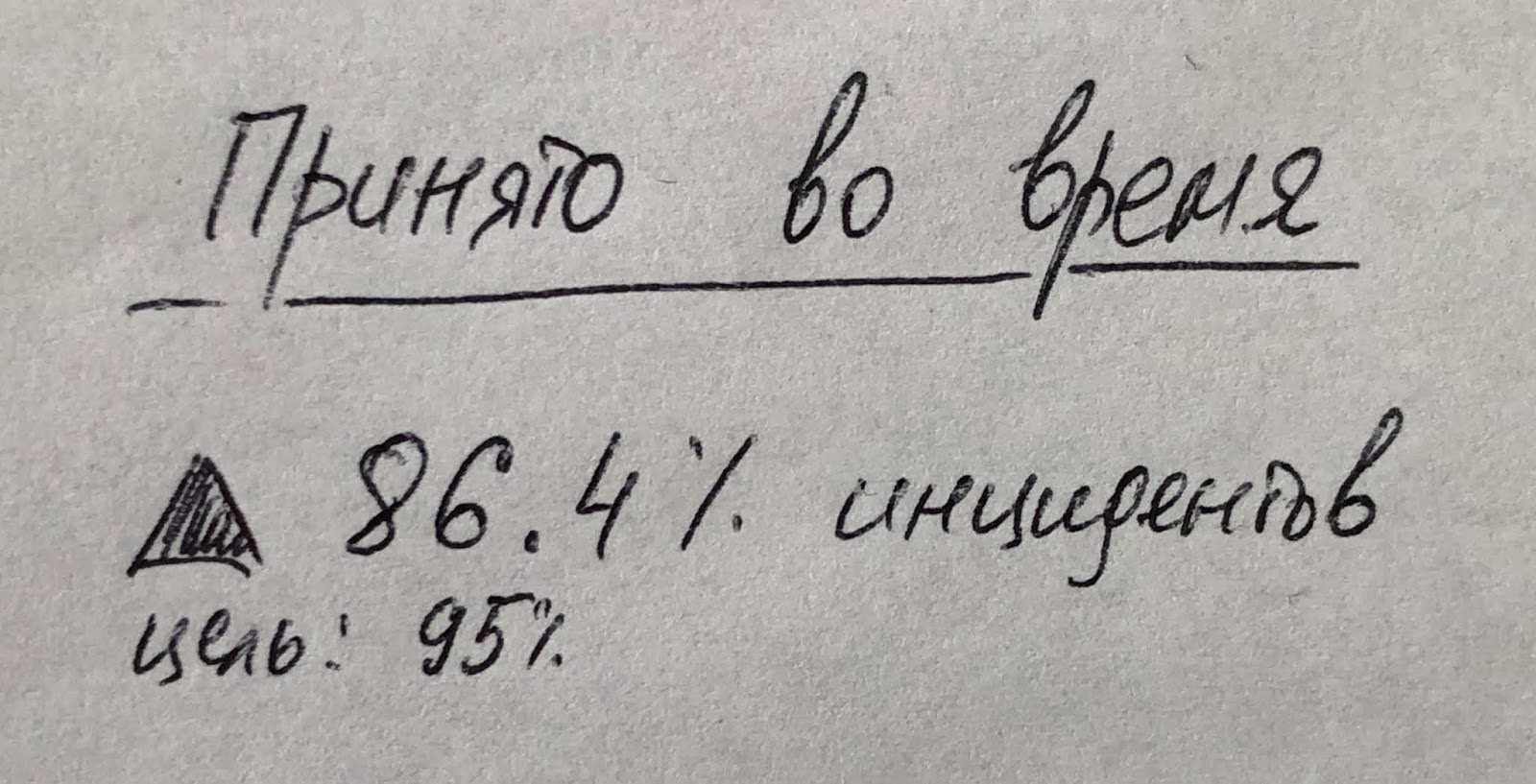

Еще одним интересным виджетом может стать «занятость аналитика». Обычно мы считаем, что человек работает весь рабочий день, с 9-ти до 6-ти или с 9-ти до 9-ти или в каком-то ином режиме, в зависимости от длительности смен. На самом же деле, может оказаться так, что аналитик отлынивает от работы, много времени отдыхает, перекуривает и т.п. Поэтому занятость аналитика, которая оценивается как отношение суммарного времени, затраченного на работу с инцидентами (легко оценивается в IRP/SOAR-платформе), к общей длительности смены, является очень хорошим показателем. На виджете ниже вы видите, как его можно визуализировать. Мы видим не только текущее значение для всех аналитиков или какого-то конкретного из них, но и целевое значение. В рабочей версии виджета мы можем использовать фотографии аналитиков и цифровую дифференциацию в зависимости от попадания или нет в целевые значения.



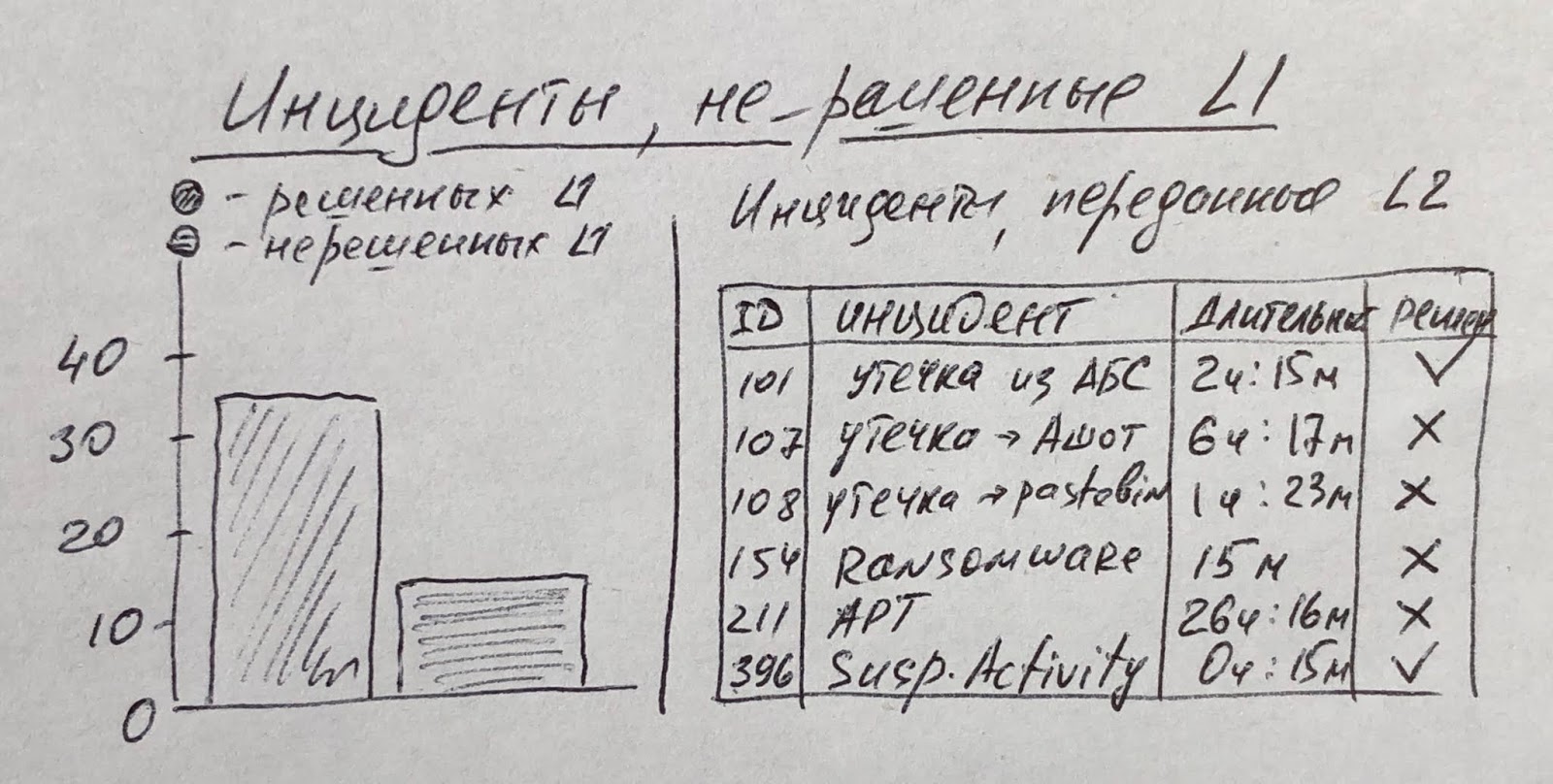
Ну а дальше мы можем визуализировать инциденты/тикеты по различным срезам и с привязкой к разным их атрибутам.
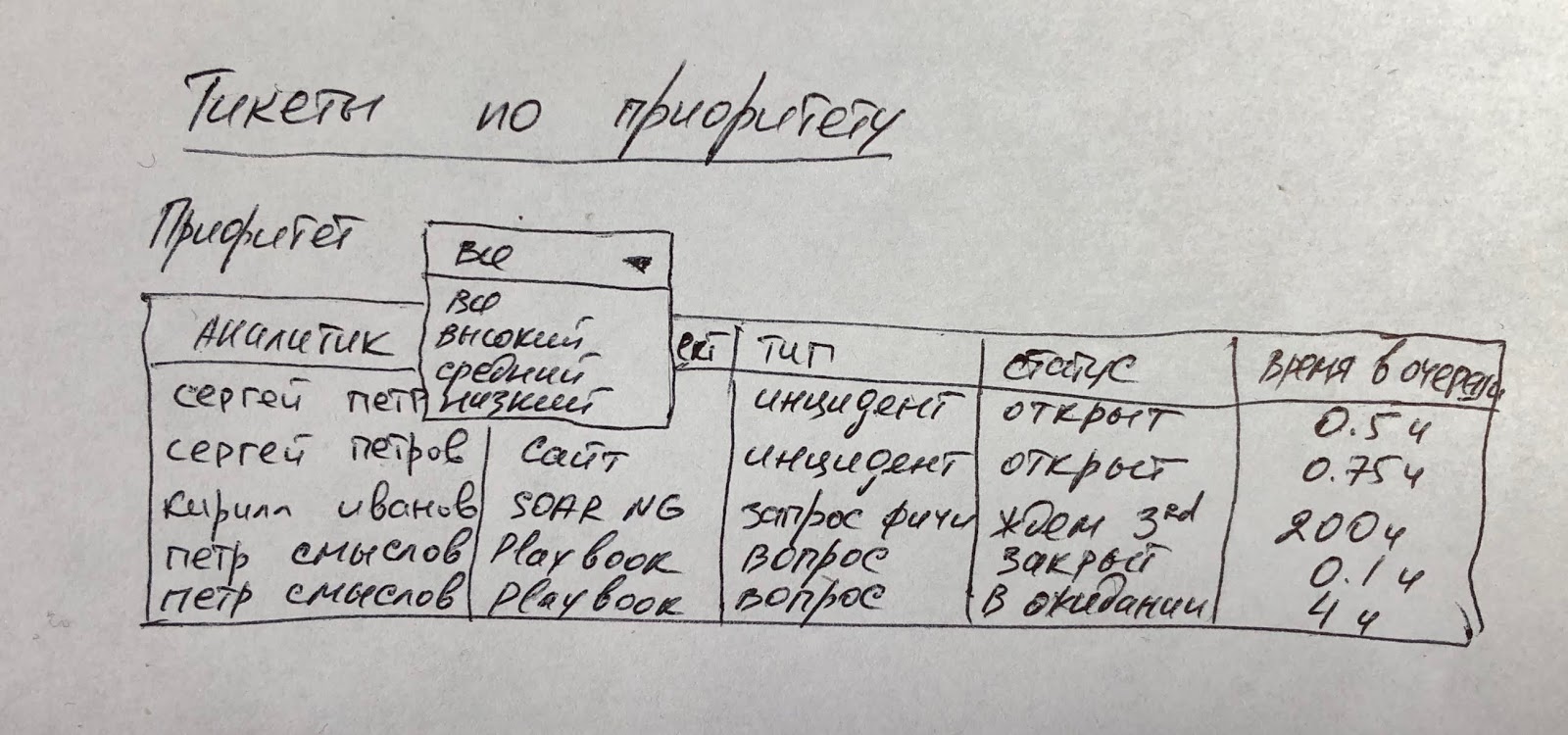
Вообще тема визуализации метрик ИБ в виде отчетов и дашбордов сегодня очень мало кем прорабатывается. Она гораздо сложнее, чем даже просто тема измерения эффективности SOC. Ну считаете вы классические TTD/TTC/TTR. Может быть вы добавляете к ним MTTI, MTTQ, MTTV или MTTM. А может быть вы все-таки оцениваете еще и другие параметры (число переданных на L2 инцидентов, число открытых инцидентов критического уровня, точность эскалации инцидентов или число пострадавших активов/устройств). Допускаю. Но вот правильно их сочетать и визуализировать — это совершенно иное умение, которое и помогает быстро принимать правильные решения, направленные на улучшение деятельности центра мониторинга.
ЗЫ. Прикинул тут на досуге — уже накопилось материала на отдельный курс по дашбордам в ИБ. Думаю, еще покумекаю над ним, добавлю про варианты реализации дашбордов, и запущу на какой-нибудь платформе для онлайн-обучения.






