
На PHDays, помимо секции по open source, я еще модерировал секцию «Скандалы, интриги, расследования: как защититься от утечки данных», на которой от моих вопросов не очень активно, но отбивались компании Positive Technologies, «ИБ Реформ», НТЦ Заря, РТ-ИНФОРМ и Infowatch. Все-таки тема утечек сегодня стала с одной стороны очень и очень актуальной, но именно со стороны ее публичности и умения реагировать компаний-жертв на факты опубликования СМИ или различными телеграм-каналами доказательств кражи данных. С другой стороны, у нас часто ассоциируется эта тема с DLP, причем часто с DLP в их классическом понимании 10-15-тилетней давности.
Меня лично всегда удивляла попытка решить проблему утечки с помощью DLP, забывая про то, что все последние крупные утечки происходят совсем по другим каналам — то MongoDB в Интернет смотрит, то через разрешенный DNS утечет, то через пробив со стороны легальных сотрудников, то через каналы, неконтролируемые DLP. Борьба с утечками в данном контексте — это задача комплексная, требующая целой архитектуры, учитывающей как технические, так и организационные и, самое главное, юридические аспекты.
Допустим, вы работаете в международной компании, офисы которой представлены в разных странах мира, имеющих разное законодательство в части мониторинга работников, применения решений класса DLP, разные риски и т.п. Очевидно, что вы не будете всех под одну гребенку грести и будете дифференцировать свои офисы, разбив их на зоны. Например, вот так:
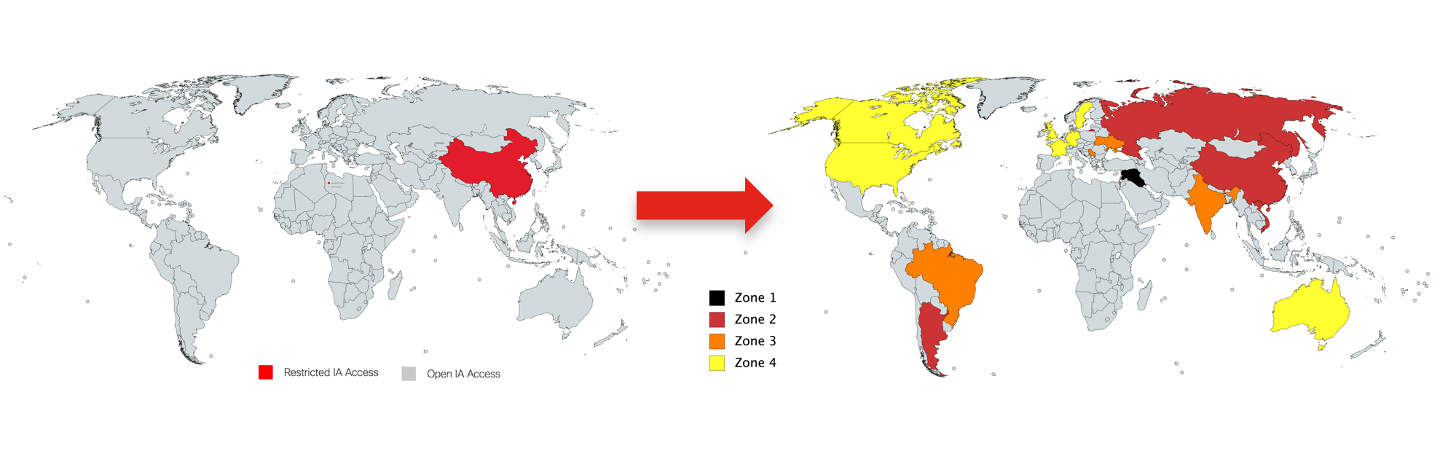
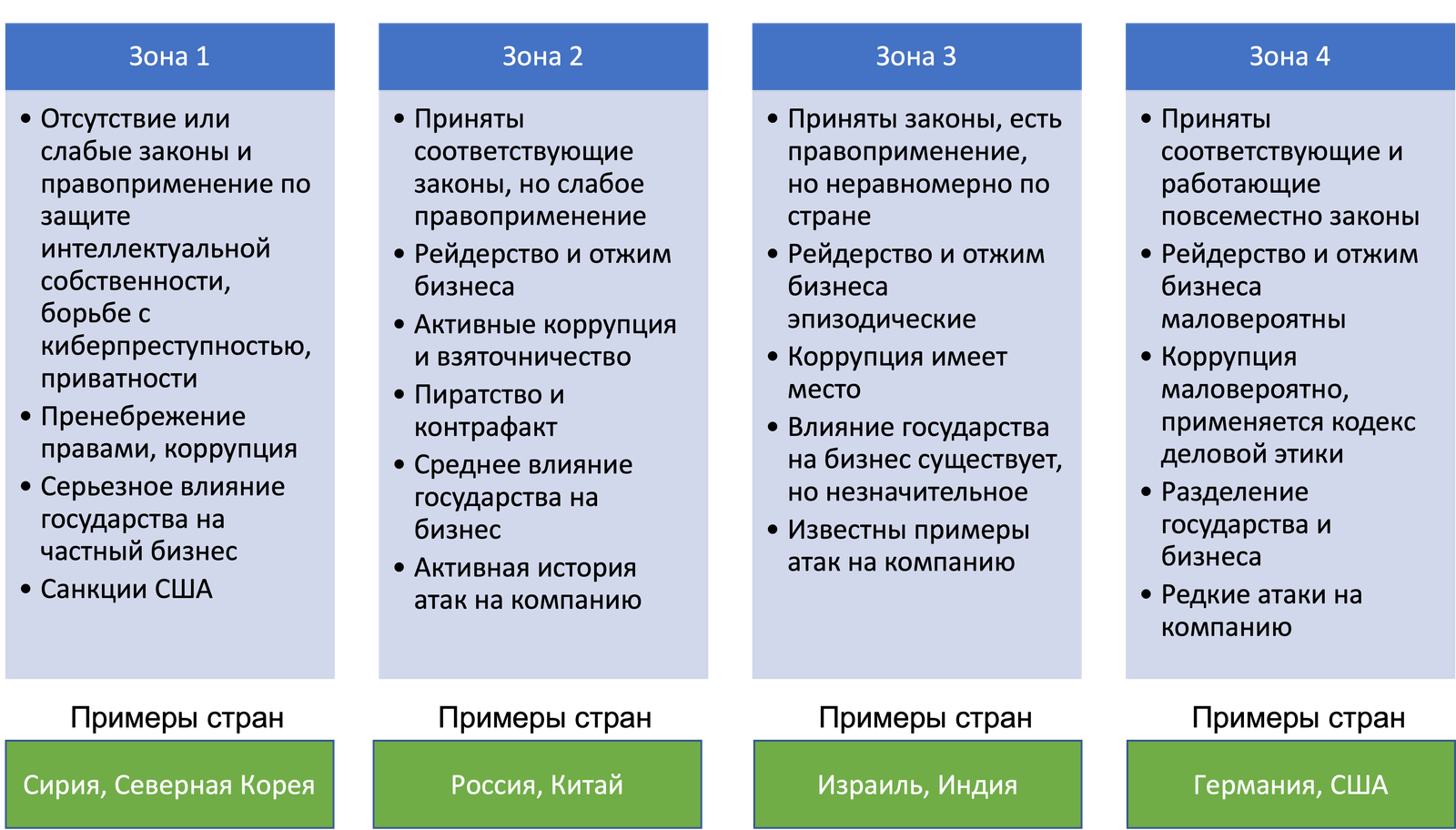
В зависимости от зоны могут быть использованы различные механизмы защиты — от контроля доступа и применения средств мониторинга и заканчивая решениями класса UEBA и DLP на уровне сети или оконечных устройств. На загнивающем и все более отделяющемся от нас железным занавесом Западе, DLP больше используются для выполнения законодательства — мониторинга номеров кредитных карт, номеров соцстрахования и т.п. У нас же эти решения больше сфокусированы именно на слежении за работниками, что признается неэтичным и нарушающим конституционные нормы во многих демократичных странах (но в отдельных это делается).
А вот с мониторингом интересная история. Часть участников дискуссии считает вообще бессмысленным выделять борьбу с утечками в отдельное направление — расследовать все равно надо все инциденты, а уж что они из себя представляют — утечку, шифровальщика или превышение привилегий — не так уж и важно. И заводить даже DLP, не говоря уже о UEBA и других средствах мониторинга утечек (например, NDR), можно без проблем в SOC. Правда, мне приходилось сталкиваться с организациями, в которых борьба с утечками выделена в отдельное направление и даже находясь в SOCе оно подчиняется своим правилам и использует свой технологический стек.
Такое же, достаточно четкое, деление на секции коснулось и вопроса обращения в суд за защитой своих прав по поводу утечки информации. Чтобы это сделать наиболее эффективно, предварительно надо определиться со списком конфиденциальной информации, ввести режим коммерческой тайны и выполнить ряд других организационных мероприятий. Противники этого подхода считают, что это все не работает или требует слишком больших затрат, несоизмеримых с получаемой выгодой. Я лично тоже считаю, что предусмотренный законом «О коммерческой тайне» набор шагов, плохо ложится на современное предприятие и электронный документооборот. Но есть и сторонники такого подхода, который присущ государственным структурам и ВПК.
Не удалось мне на секции раскрыть тему классификации данных, которая является, на мой взгляд, основной проблемой для автоматизации процесса обнаружения утечек чувствительной информации. Ушедший из России Gartner тоже считает, что тема эта еще не проработана и я склонен с ним согласиться; хотя ситуация и чуть лучше, чем она была несколько лет назад, когда я писал на прекратившем свое существование портале bankir.ru большой материал по классификации информации.
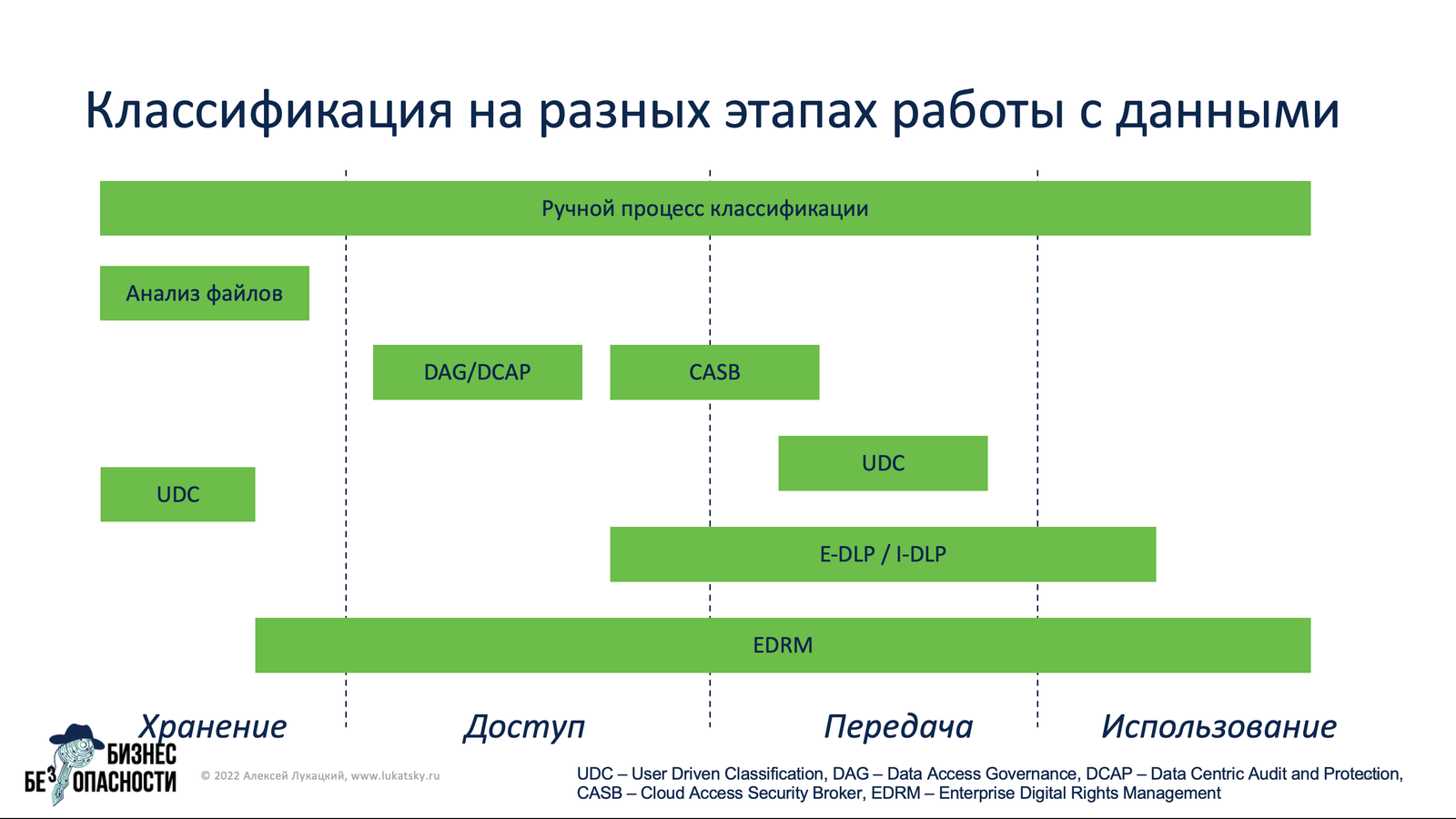
Если вспомнить, что данные у нас могут появляться на этапе хранения, передачи и обработки, и происходить это может как на оконечных устройствах, в сети, в облаках и т.п., то одним решением эту задачу не решить и нужно использовать целый набор технологий, которые позволят классифицировать и затем контролировать и мониторить ценную информацию. И речь не идет об устаревших технологиях типа масок или ключевых слов — сегодня активно начинает применяться машинное обучение, но даже оно пока не решило проблему до конца. А без ее решения говорить о эффективном процессе борьбы с утечками достаточно сложно и подход, озвученный на секции PHDays, заключающийся в том, что расследовать надо все, не выделяя особо утечки от иных типов инцидентов, выглядит вполне разумным. Ну или придется ограничивать контролируемую информацию только отдельными ее видами и хранилищами.
Не имея возможности из-за ограничений по времени обсудить все вопросы, которые я хотел (например, «как реагировать, если вас шантажируют раскрытием информации об утечке у вас?», «как разграничивать доступ к информации в условиях agile и Infrastructure-as-a-Code?» или «есть ли будущее у специализированных поставщиков услуг Data Breach Response?»), я завершил нашу дискуссию темой, которую днем ранее поднял Владимир Бенгин из Минцифры, а именно обсуждением оборотных штрафов за утечку персональных данных. На заданный всем участникам вопрос о том, видят ли они перспективу у этого законопроекта и поможет ли он снизить число утечек, большинство сошлось во мнении, что рынок ИБ точно получит новый толчок, но вот к снижению числа утечек это не приведет, возрастет только цена утечки (пробива). И на этой «позитивной» ноте для меня закончился одиннадцатый PHDays 🙂








Cui prodest?
Выгодно что?
По поводу классификации данных. ИИ это все здорово. Но на практике простая маркировка (нанесение грифа), если ее делать, уже даёт большой профит.
Проблема только в человеке, которому маркировать документы лень.
Как решение — описал тут скрипт как автоматом наносить гриф на pdf файлы
https://service.securitm.ru/actions/55ac33fb-0f1b-49b1-9b9c-992ba8835e9c#comment_273
С структурированной информацией проблем как раз меньше всего, хотя попытка навесить эту задачу на пользователя — тупиковая, как мне кажется. А что делать с динамически формируемой информацией, мультимедиа-информацией, базами данных и т.п.?
Соглашусь что для БД маркировка не подходит. Мы умудрялись по DLP ловить какие то кусочки из БД, но это такая себе защита, эффективная с «долей вероятности».
Она вообще не подходит для любой динамически обрабатываемой информации. Только анализ и принятие решений на лету, с чем и проблемы